一面心得
要寄
刚刚了解了其他竞争者,完了完了完了完了,什么康奈尔的phd和清北的硕士,我纯纯炮灰一个啊。
二面心得
没想象中的那么难,非常意外。我现学的spark和sql没有谈很多,倒是聊了很多的深度学习的东西。
###
Microsoft真是一家非常神奇的企业,我之前的论文经历和STCA的项目较为匹配,工程测试和coding也很顺利,决定去stca了。
实习准备
提升 Coding 能力是重中之重
LRU缓存问题
为了实现本题的操作,需要用一个哈希表和一个双向链表,一般面试官期望读者能实现一个简单的双向链表,而不是简单的使用语言自带的链表,此时只需要记忆python的这个数据结构。
OrderedDict
OrderedDict
OrderedDict
OrderedDict
OrderedDict
OrderedDict
OrderedDict
OrderedDict 简单来说Order Dict 就是简单的哈希映射
如果想让字典有序,可以使用collections.OrderedDict,它现在在C中实现,这使其快4到100倍。然后最重要的是OrderedDict是记住键首次插入顺序的字典
这题太难,你在面试的时候肯定做不出来,去做简单的
微软二面感想:
Python 八股文
赋值、浅拷贝和深拷贝的区别?
- python好像没啥好考的,chatGPT时代了
机器学习八股文
什么是回归和分类
最小二乘法
无监督学习 (聚类算法)
- k-Means K 均值
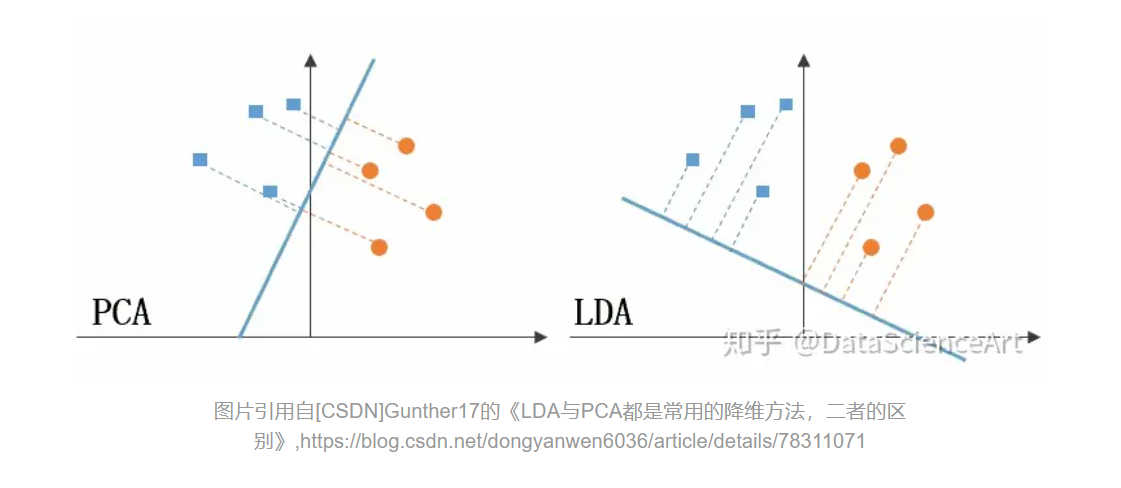
- 线性判别分析 LDA和主成分分析 PCA,(常见的降维方法)

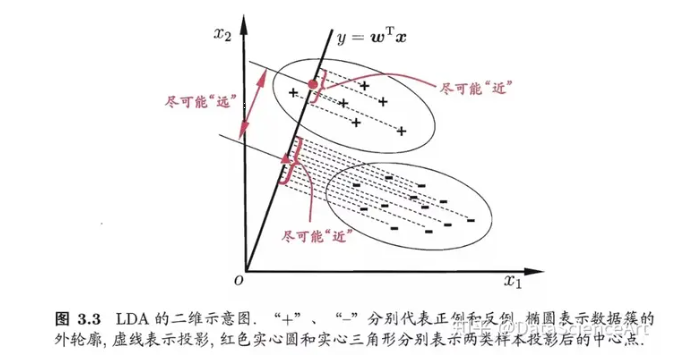
- 图下面是PCA的降维思想,它所作的只是将整组数据整体映射到最方便表示这组数据的坐标轴上
- 信息熵
- 数据归一化
- 将数据映射到[0,1]之间
- 减少很大很大那些值
- boost(AdaBoost 五步走)
- 先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续获得更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合。
分类 (离散)
- 决策树
- 线性回归
- y= w1x1+w2x2+e,e为误差服从均值为0的正态分布,根据房间数量、邻里环境和年龄(自变量)来预测房价(因变量)
- 用于回归
- 逻辑回归
- 逻辑回归等于 线性回归+sigmoid
- 用于分类
- 根据房间数量、邻里环境和年龄(自变量)预测房价超过 50 万美元(因变量)的概率。
- 逻辑回归等于 线性回归+sigmoid
- SVM
- 朴素贝叶斯
- KNN 监督学习
回归 (连续)
-
线性回归
-
L1正则化
-
L2正则化
深度学习
- SGD 随机梯度下降
- 召回率\准确率
什么是正则化 L1 L2
深入理解L1、L2正则化 - ZingpLiu - 博客园 (cnblogs.com)
要求会默写公式以及讲明白正则化的作用(不容易过拟合),这里的W是特征向量,wi是向量中间的值

决策树
决策树是一种树结构,从根节点出发,每个分支都将训练数据划分成了互不相交的子集。分支的划分可以以单个特征为依据,也可以以特征的线性组合为依据。决策树可以解决回归和分类问题,在预测过程中,一个测试数据会依据已经训练好的决策树到达某一叶子节点,该叶子节点即为回归或分类问题的预测结果。
从概率论的角度理解,决策树是定义在特征空间和类空间上的条件概率分布。每个父节点可以看作子树的先验分布,子树则为父节点在当前特征划分下的后验分布。
样本少怎么办
K则交叉验证将训练集分为K份,然后进行K次交叉验证,每次使用K-1份作为训练样本数据集,另外一份作为测试集;
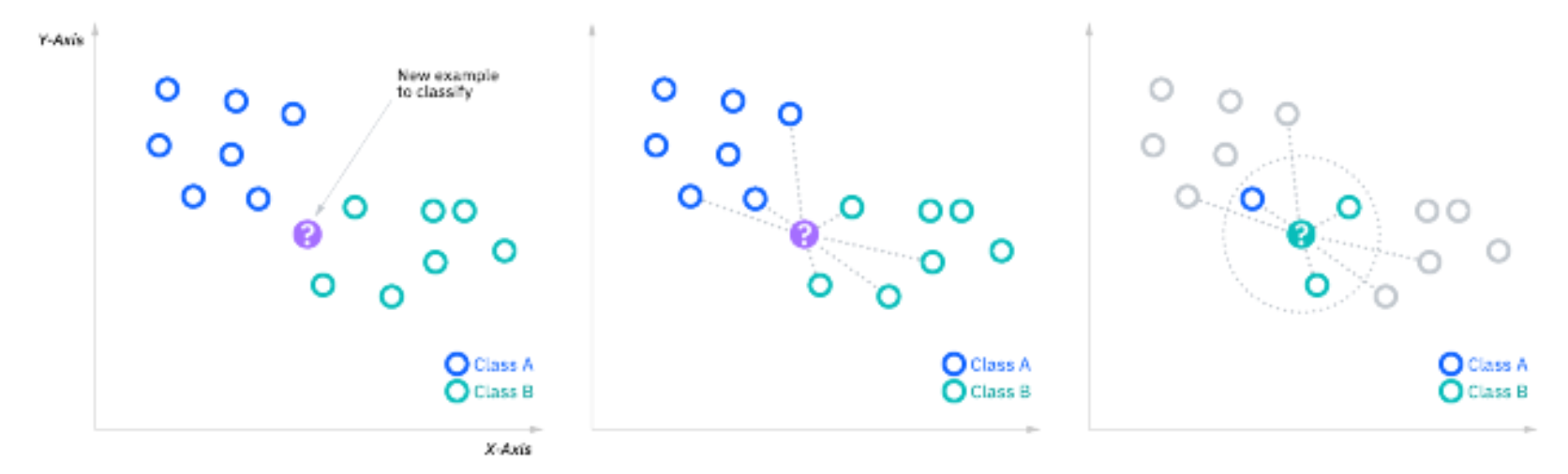
KNN和 k-means
K-means 用于将已有的杂乱无章的数据分成k簇,没有标签,所以是无监督:
- 随机选择k个点。
- 遍历数据集-对数据中的每个点计算到最近质心的距离,离哪一个近就归类到哪个簇。
- 对每个簇(或者说集合)重新计算质心的位置。
- 计算当前质心与原来质心之间距离,如果这个距离大于某个阈值,说明质心不稳定,重复2-4重复迭代。
- 直到新聚类中心和旧聚类中心不再移动
改进:类似于SGD 的mini K-means和优化初始化方法的
K-NN 非常简单的一个点归类的问题,就是 有一个点没有分类(或者有些数据没有补全)我们的任务是补全这个值,简单的就是k个邻近值的平均
贝叶斯
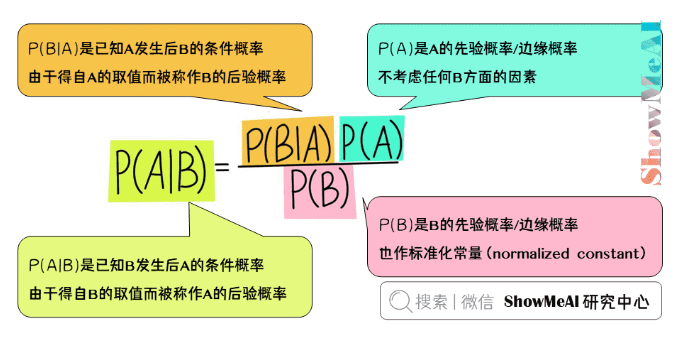

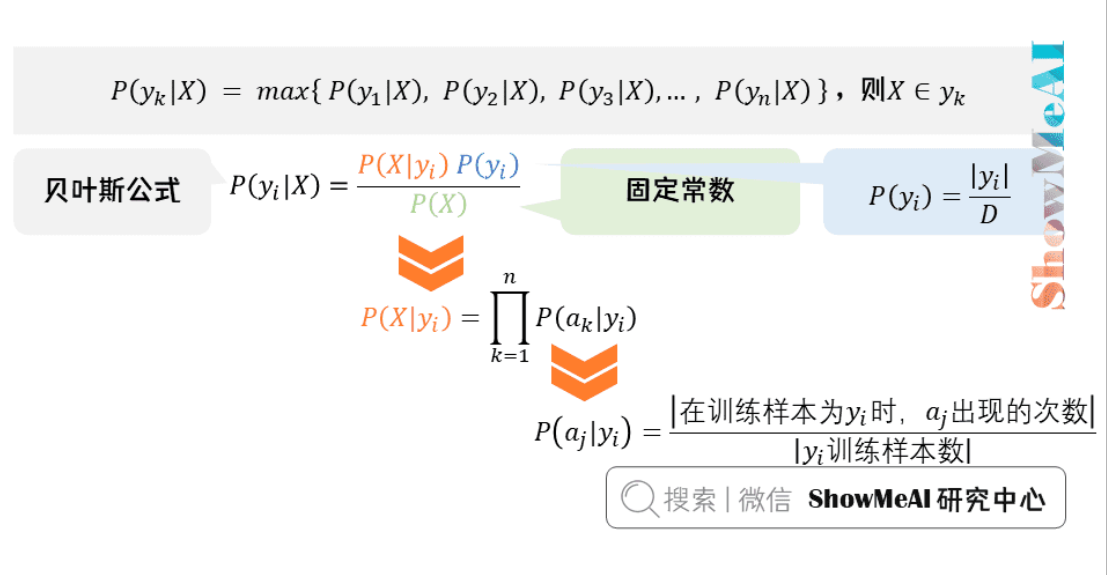
什么是协同过滤
而基于协同过滤的推荐,又分三个子类:
基于用户的推荐(通过共同口味与偏好找相似邻居用户,K-邻居算法,你朋友喜欢,你也可能喜欢);
基于项目的推荐(发现物品之间的相似度,推荐类似的物品,你喜欢物品A,C与A相似,可能也喜欢C);
基于模型的推荐(基于样本的用户喜好信息构造一个推荐模型,然后根据实时的用户喜好信息预测推荐)。
Spark 八股文
任务清单
-
map reduce 机制
-
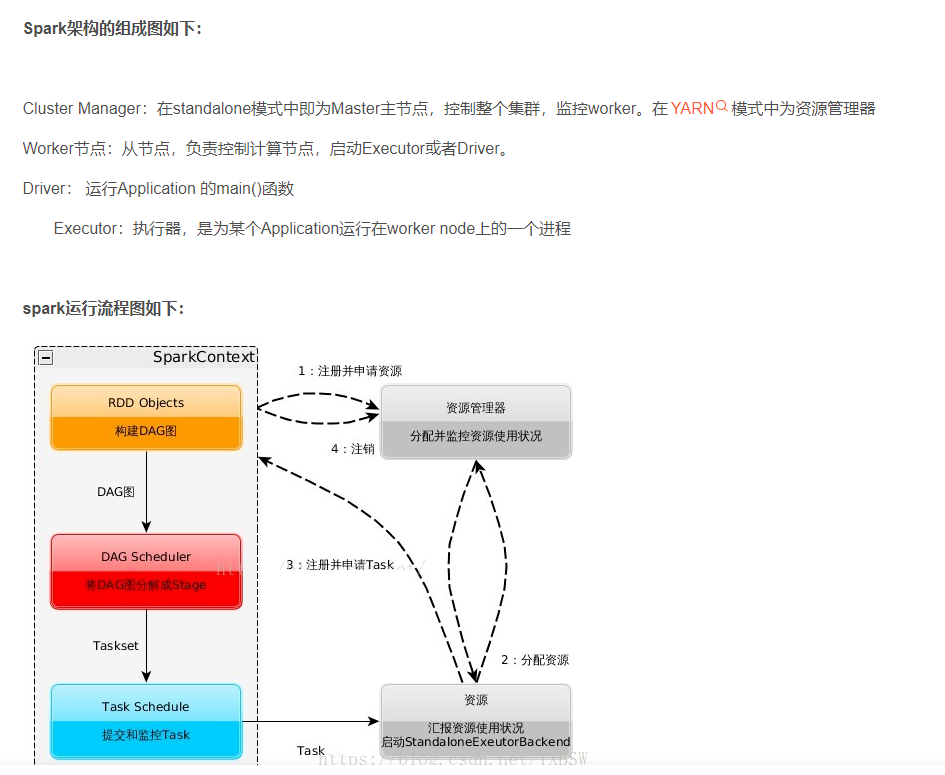
Spark 工作流程
-
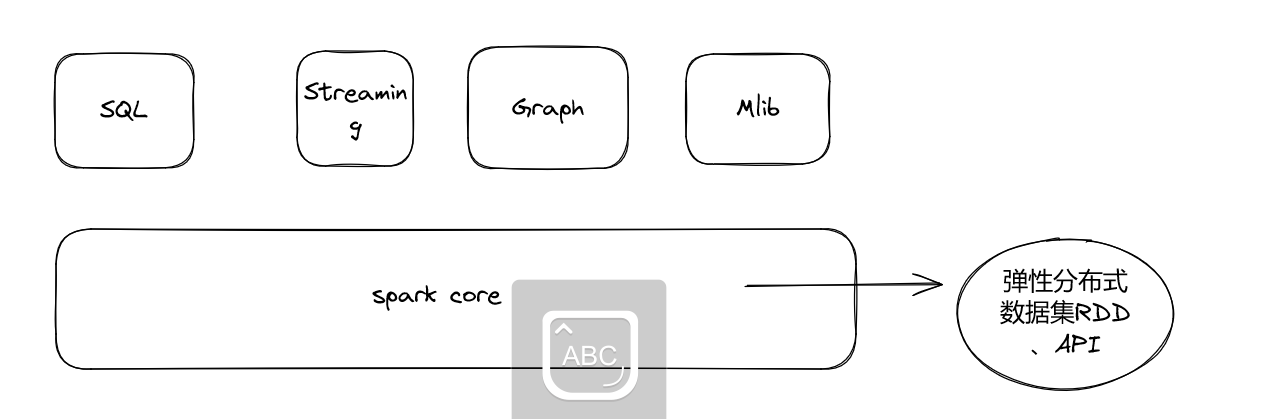
Spark 六大组件
-
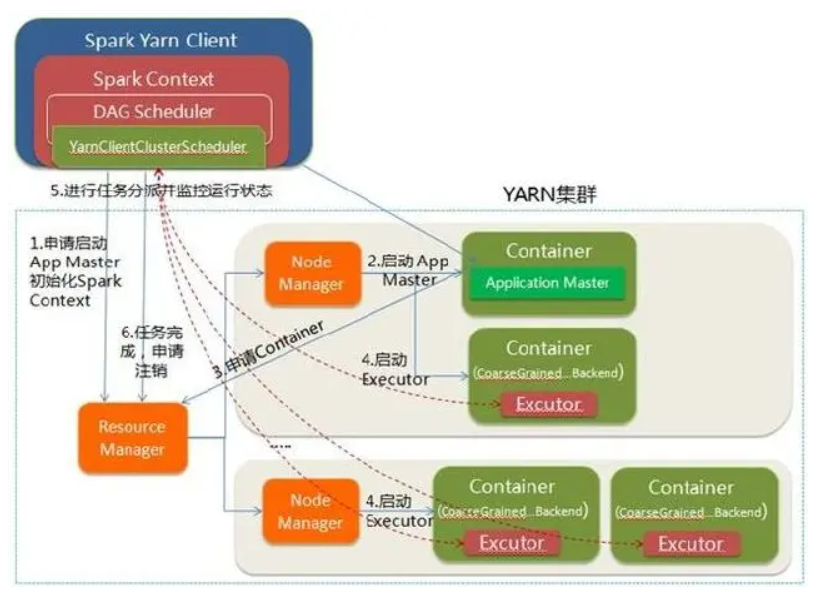
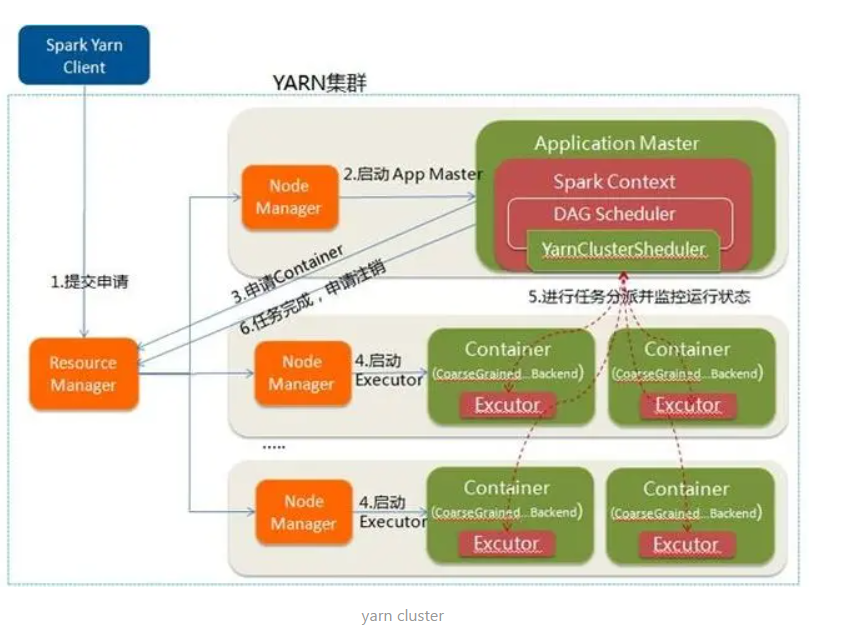
Spark On Yarn 是什么
-
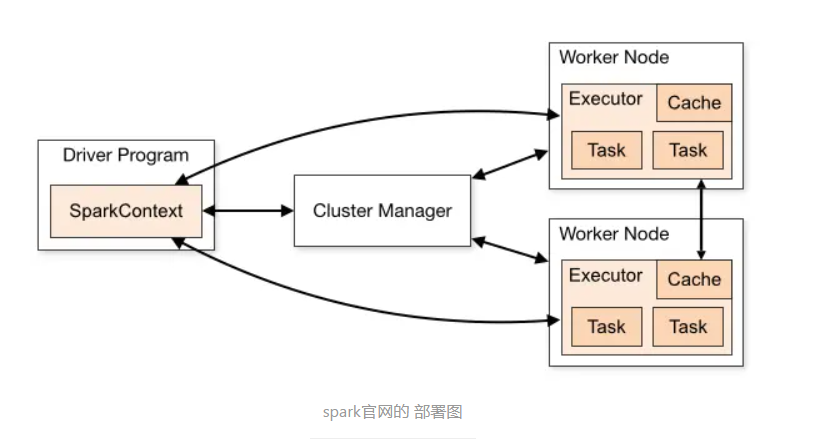
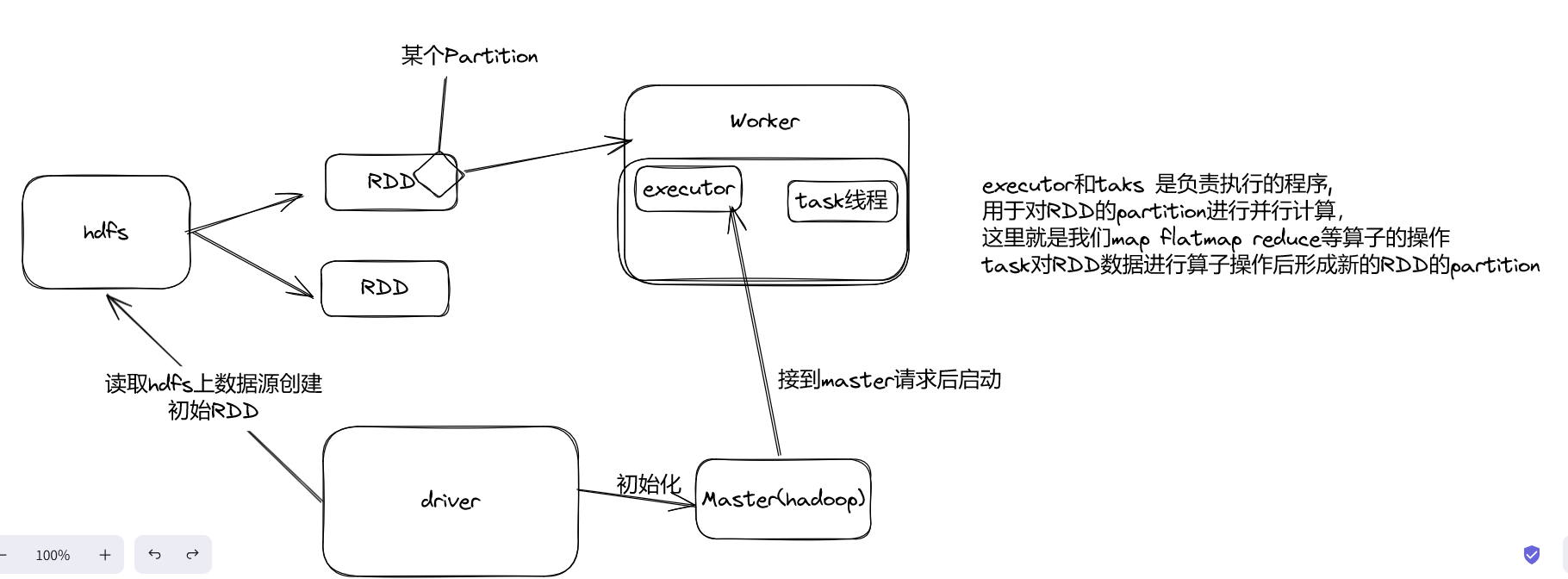

Spark 和 python 的集合Pyspark,本质是JVM外面套了一个socket
- Yarn Cluster 和 Yarn Client
- RDD 宽依赖和窄依赖
- 算子???
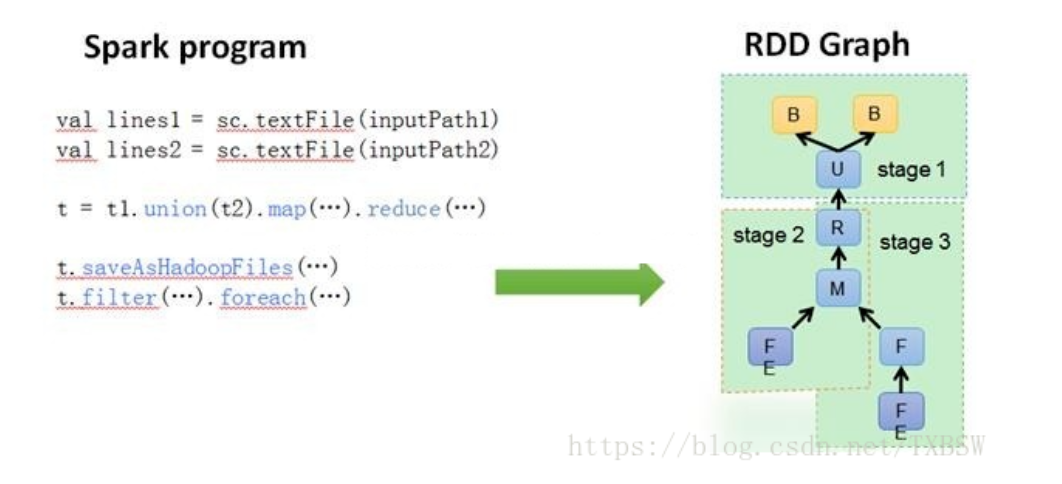
- job stage task
- Spark Hadoop 的区别和MapReduce的区别
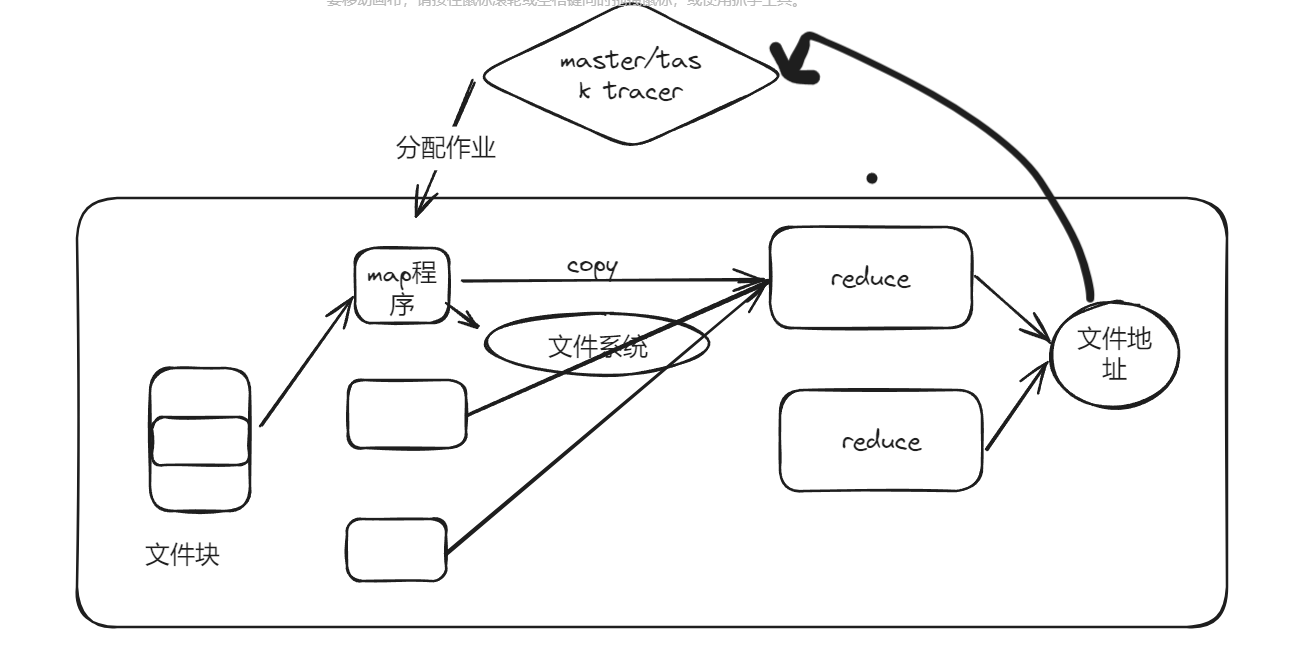
Task: 被送到某个Executor上的工作单元,但hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责
Job: 包含多个Task组成的并行计算,往往由Spark(火花) Action触发生成, 一个Application中往往会产生多个Job
Stage: 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方
DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法,如下图
Yarn模式
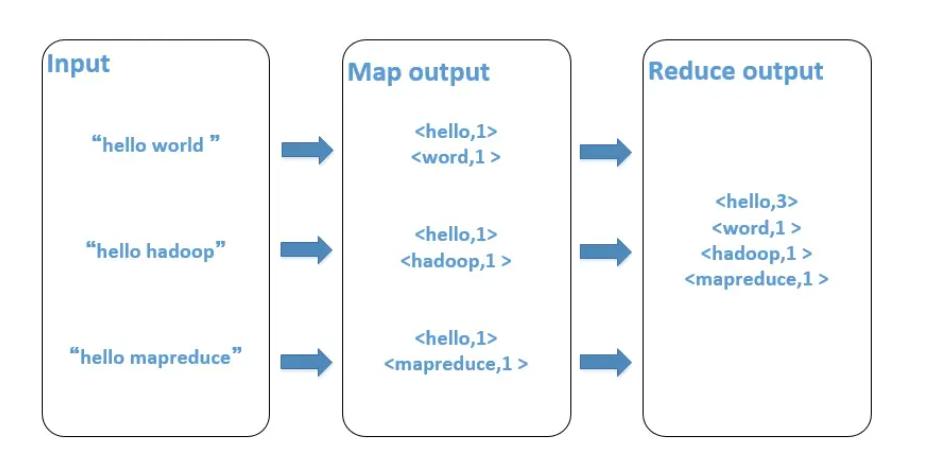
Map Reduce
注意 reduce接收的是所有map 的输出,时间控制在五分钟,注意中间的sort,最后注意所有中间状态都是存在不同机子里面的
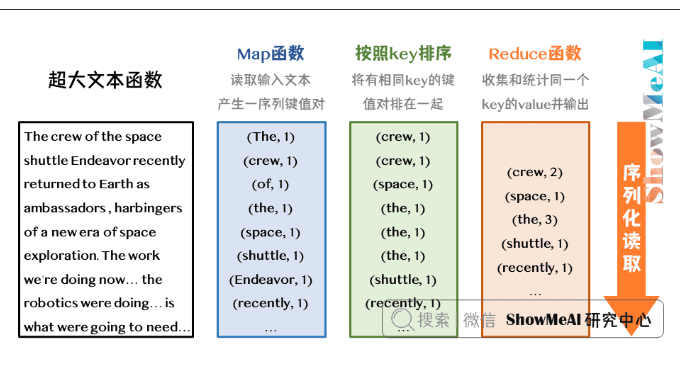
注意其中的sort函数
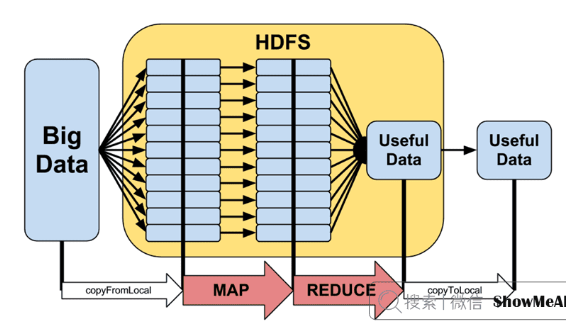
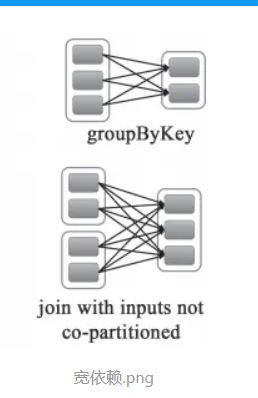
一张图理解 宽依赖和窄依赖
窄依赖就是指父RDD的每个分区只被一个子RDD分区使用,子RDD分区通常只对应常数个父RDD分区,如下图所示【其中每个小方块代表一个RDD Partition】

宽依赖就是指父RDD的每个分区都有可能被多个子RDD分区使用,子RDD分区通常对应父RDD所有分区,如下图所示【其中每个小方块代表一个RDD Partition】
Hadoop 和 Spark的不同
Hadoop 只有map 和reduce
Spark 有先后顺序
Hadoop 中间那些结果要存储在文件系统里面
Spark 直接在内存中按照次序处理
SQL
语法 组内排序 rank
一句话概括就是
若某一数据字段与它前面数据字段相同,则这个数据字段的排名变成他前面数据字段的排名。
文字理解可能比较绕,简单理解为排名从 “1,2,3,4,5,6,7” 变为 “1,2,2,4,5,5,7”
语法 order by XXX
所谓 order 默认都是 ascendinng的 descending, sql中的所谓升序和降序就是在后面加asc 和 desc 前4个字母
3、 复合排序,先按列 c1 升序排列,再按 c2 降序排列
select * from tablename order by c1 asc, c2 desc;
#### 语法 order by XXX
去重,总之就是distinct, group by, row number

-- 下方的分号;用来分隔行
select distinct user_id
from Test; -- 返回 1; 2
select distinct user_id, user_type
from Test; -- 返回1, 1; 1, 2; 2, 1
select user_id
from Test
group by user_id; -- 返回1; 2
select user_id, user_type
from Test
group by user_id, user_type; -- 返回1, 1; 1, 2; 2, 1
select user_id, user_type
from Test
group by user_id;
-- Hive、Oracle等会报错,mysql可以这样写。
-- 返回1, 1 或 1, 2 ; 2, 1(共两行)。只会对group by后面的字段去重,就是说最后返回的记录数等于上一段sql的记录数,即2条
-- 没有放在group by 后面但是在select中放了的字段,只会返回一条记录(好像通常是第一条,应该是没有规律的)
语法 row_number
row_number
row_number 是窗口函数,语法如下:
row_number() over (partition by <用于分组的字段名> order by <用于组内排序的字段名>)
其中 partition by 部分可省略。
语法 left join \inner join
select * from Visits v left join Transactions t on v.visit_id=t.visit_id where transaction_id is null
一般来说,left join 会保存用于合并的选项比如表a和表b合并会变成下面这样,在两个表中都有的visit_id会变成两列,所以此时切忌不要选择这个作为下一轮查询的对象,你可以使用a.visit_id或者b.visit_id区分这两列
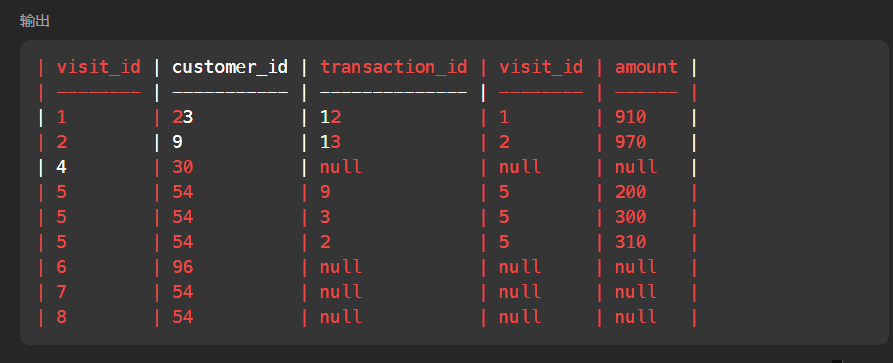
INNER JOIN 关键字在表中存在至少一个匹配时返回行。
# Write your MySQL query statement below
select b.id from Weather a inner join Weather b where timestampdiff(day,a.recordDate,b.recordDate)=1 and a.temperature<b.temperature
# 使用 笛卡尔积加上计算时间差值的东西 timestampdiff
语法 group by
所谓 group by ,是用于配合 count 和sum的函数使用的东西,用于将多个

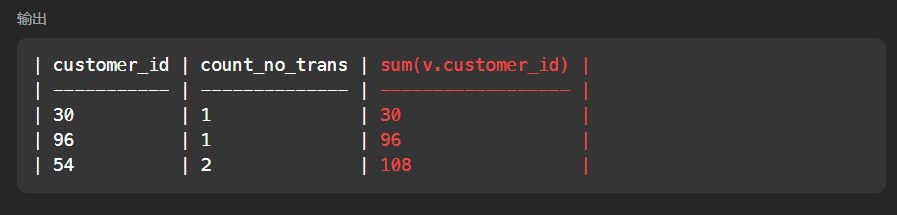
select v.customer_id,count(*) count_no_trans,sum(v.customer_id) from v group by v.customer_id
# 执行完毕后就变成了下面这个表,但是注意一般要重命名
力扣基础五十
一遍过
不记得了
测试看样例后过
# Write your MySQL query statement below 595题目
select name,population,area from World where area>=3000000 or population>=25000000
英文审题问题,注意 or
# Write your MySQL query statement below
select tweet_id from Tweets where char_length(content)>15
# 注意 char_length 这个用于计算英文单词数目
# Write your MySQL query statement below
select unique_id,name from Employees e left join EmployeeUNI eu on e.id=eu.id
# 注意left join 语法一般为 from A a left join B b on a.XX=b.xx
# 577
# Write your MySQL query statement below 注意这些外键的玩意
select e.name,b.bonus from Employee e right join Bonus b on e.empId=b.empId where b.bonus<1000
新函数
# Write your MySQL query statement below
# 学习 if round avg 等内置函数
select a.user_id,round(avg(if(b.action='confirmed',1,0)),2) confirmation_rate
from Signups a left join Confirmations b on a.user_id=b.user_id
group by a.user_id
# 位运算
select *
from cinema
where description <> 'boring' and id & 1
order by rating desc;
#要考虑到空值的情况 注意这个
select p.product_id, ifnull(round(sum(price * units) / sum(units), 2), 0) as average_price
from Prices p
left join UnitsSold u on u.product_id = p.product_id
and u.purchase_date between p.start_date and p.end_date
group by p.product_id
# Union 放置于select 之前 用于整体去重
UNION自动去重(相对union all)
看题解后过
# Write your MySQL query statement below
select distinct(author_id) id from Views where author_id=viewer_id order by author_id # 学习distinct的用法
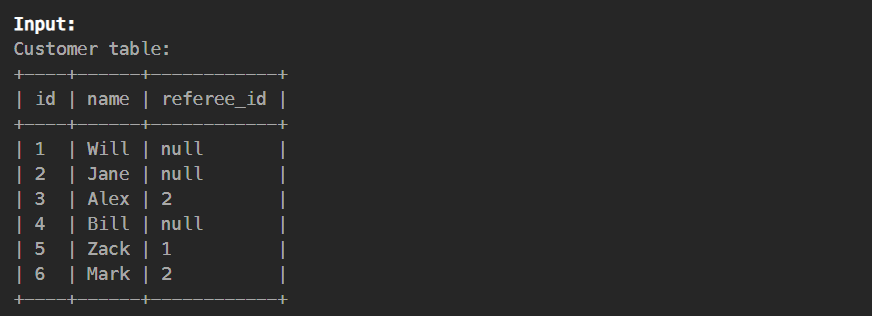
# https://leetcode.cn/problems/find-customer-referee/?envType=study-plan-v2&envId=sql-free-50
简单的=或者!=或者某些版本中的<>只能判断基础的数据类型,只有is(相当于等号)既能判断null
select name from Customer where referee_id is null or referee_id != 2
或者简单的转换null为0 ifnull(referee_id,0)
select name from Customer where ifnull(referee_id,0)!=2 # 但是会有问题
外键 内键
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录,以左边为主,右边的如果找不到就是null
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录,以右边为主,
如果左边大于右边,left join 有 null,rigth join没有
例如 如果 左边为4 右边为2 ,那么left join结果有四行 right join 结果只有2行
select e.name,b.bonus from Employee e left join Bonus b on e.empId=b.empId where b.bonus is null or b.bonus<1000
千万注意是 is null 而不是= null
高质量题型,每人每科的成绩
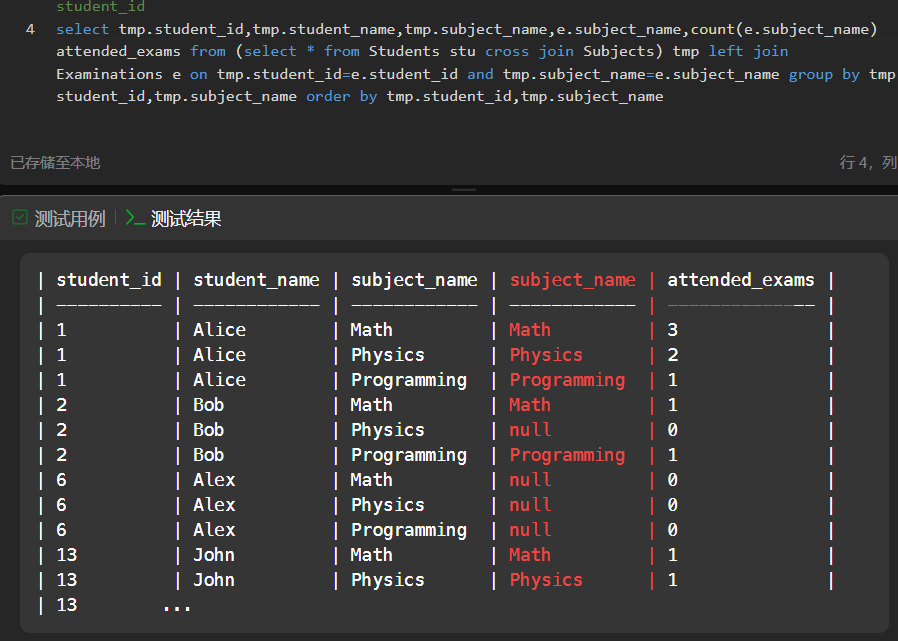
笛卡尔积类型题目,注意这个类型中,最后用于count 的列十分重要,注意排序,注意
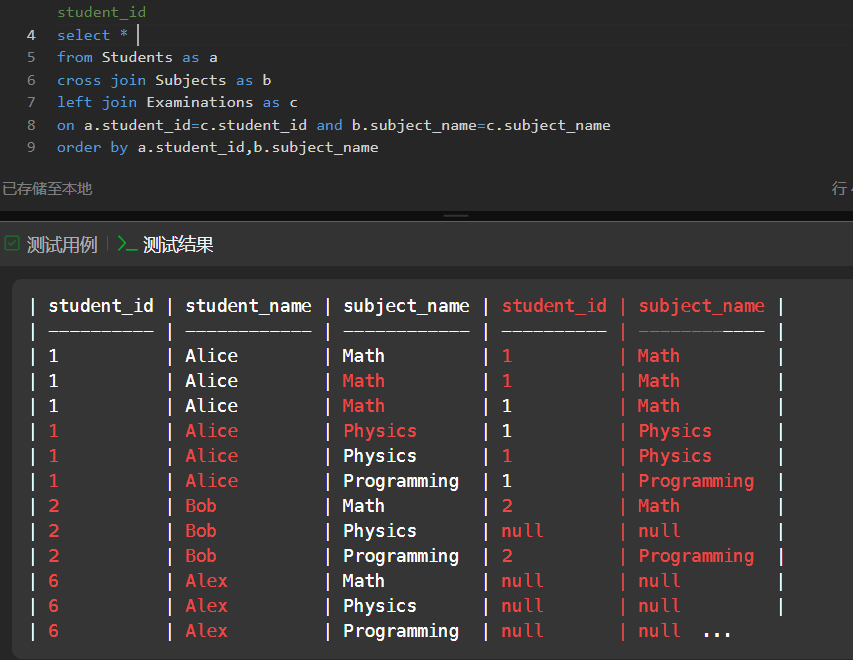
·
Python+基础算法 要寄
def quicksort(iList):
if(len(iList)<=1):
return iList
left = []
right = []
# 这个操作有点牛逼,但是注意先左后右边
for i in iList[1:]:
if i<=iList[0]:
left.append(i)
else :
right.append(i)
return quicksort(left)+[iList[0]]+quicksort(right)
