Dynamic Movement Primitives (DMP),中文译名为动态运动基元、动态运动原语等,最初是由南加州大学的Stefan Schaal教授团队在2002年提出来的,是一种用于轨迹模仿学习的方法,以其高度的非线性特性和高实时性,被应用到机器人的各个领域。时间已经过去了20年,DMP在机器人的规划控制领域也得到了长足的发展和应用,其优点得到了大家的肯定,其缺点也在逐渐被大家发现和解决。
我当年在学习DMP的过程中看论文也是看得一头雾水,后面结合论文看了加拿大滑铁卢大学的博士生Travis DeWolf(现在已经是博后了)的博文以后才算是比较理解DMP,因此在这里把所看的东西结合个人的理解做一个总结,文章有点长,其中夹杂了个人的理解和思考过程。
本文旨在从应用的角度出发,给初学者一种更加直观的方式学习DMP,尽量避免使用复杂的术语来阐述这个方法,也不会从理论上去严格证明该方法,需要了解的读者可以看原论文,在文末有参考文献列表。本文中介绍的DMP会使用Python代码实现,并在CoppeliaSim(VREP)中使用UR5机械臂来完成部分应用的仿真。
所有的代码开源在Github上,地址为:chauby/PyDMPs_Chauby (github.com)
1. DMP的基本概念
在机器人的规划控制中,我们需要事先规划参考轨迹,例如关节角度曲线、机械臂末端轨迹等,如果任务参数比较复杂多变,那么通过编程来规划参考轨迹就比较复杂了,而示教是一种比较简单直观的方法,我们可以让有经验的人带着机器人先完成一次任务,然后让机器人自动学习其中的过程,从而省去编程的复杂过程。我们希望能有一种方法,能够使用少量的参数来建模示教的轨迹,通过这些参数能够快速地复现示教轨迹,同时,还希望在复现示教轨迹的时候能够增加一些任务参数来泛化和改变原始轨迹,例如改变关节角度曲线的幅值和频率,改变机械臂末端轨迹的起始和目标位置等等,这样才能更加灵活的使用示教方法来完成实际任务。
论文作者最基本的出发点是想利用一个具有自稳定性的二阶动态系统来构造一个“吸引点”模型(attractor model),使得可以通过改变这个“吸引点”来改变系统的最终状态,从而达到修改轨迹目标位置的目的,而最简单最常用的二阶系统就是弹簧阻尼系统(PD控制器):
\[\ddot y = \alpha_y(\beta_y(g-y)-\dot y)\]其中,$y$表示系统状态(例如关节角度$\theta$),$\dot y$和$\ddot y$分别表示$y$的一阶导数和二阶导数。$g$表示目标状态,最后系统会收敛到这个状态上。$\alpha_y$和$\beta_y$是两个常数,相当于PD控制器中的P参数和D参数。
这里我们来看一下PD控制器的收敛过程,参数合适的话大致会得到如下的收敛过程:
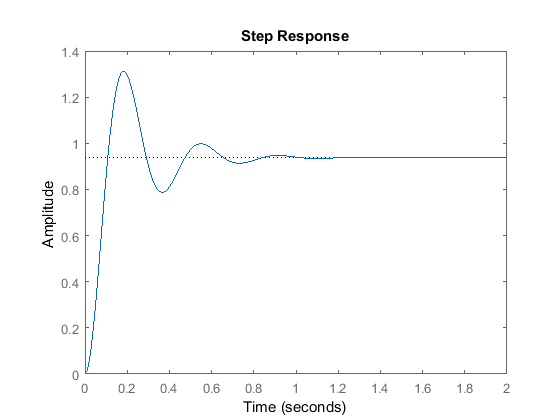
使用弹簧阻尼系统虽然能够让系统收敛到目标状态$g$,却无法控制收敛的过程量,比如轨迹的形状。那么作者就想在这个PD控制器上叠加一个非线性项来控制收敛过程量,因此,在直观上,我们可以把DMP看作是一个PD控制器与一个轨迹形状学习器的叠加:
\[\ddot y = \alpha_y(\beta_y(g-y)-\dot y) + f\]其中,上式右边的第一项就是PD控制器,而第二项$f$就是轨迹形状学习器,是一个非线性函数。这样,我们就可以通过改变目标状态$g$和非线性项$f$来调整我们的轨迹终点和轨迹形状了,这可以称之为空间上的改变。但还不够,我们还需要改变轨迹的速度,从而获得不同收敛速度的轨迹,这个可以通过在速度曲线$\dot y$上增加一个放缩项$\tau$来实现:
\[\tau^2 \ddot y = \alpha_y(\beta_y(g-y)-\tau \dot y) + f \label{DMP}\]上式即为DMP的基本公式了(由于$\ddot y = d\dot y/dt$,因此,上式左边的$\ddot y$的系数是$\tau^2$)。从直观上来看,我们可以知道,上面这个公式表明在这个动态的控制过程中,系统最后会收敛到状态$g$,并且非线性项$f$的参与会直接影响$\dot y$,也就是直接影响到收敛的过程。通过给定不同的$\tau$和$g$,我们就可以在示教曲线的基础上得到不同目标状态以及不同速度的轨迹了。
那么,这个非线性项$f$具体怎么构造呢?要知道,我们叠加$f$的目的就是为了改变轨迹的形状为我们期望的形状,那么,什么样的非线性函数可以很容易的拟合各种形状的轨迹,而且方便我们进行参数的调整呢?原大佬作者是这样考虑的,通过多个非线性基函数的归一化线性叠加来实现,因此,非线性函数$f$可以表示为:
\[f(t)=\frac{\sum_{i=1}^{N} \Psi_{i}(t) w_{i}}{\sum_{i=1}^{N} \Psi_{i}(t)}\]在原论文中,作者把$f$称之为forcing term,意为给PD控制系统增加的一个“外力”(为什么是力?因为$f$直接影响到轨迹的加速度项$\ddot y$,相当于是一个外力的作用),用这个力去改变轨迹的形状。其中,$\Psi_i$是基函数,其实,在后面我们可以看到,这个基函数所使用的就是高斯基函数(径向基函数),$w_i$为每个基函数对应的权重,N为基函数的个数。我们通过给定不同的基函数和对应权重就可加权得到复杂的轨迹了。
此时,非线性项$f$与时间$t$是高度相关的,无法直接叠加其他的动态系统进来,也无法同时建模多个自由度的轨迹并让它们在时间上与控制系统保持同步。因此,对于离散型DMP,论文使用了一个与时间无关的量$x$来替代时间$t$,而对于节律型DMP,论文使用了一个与时间无关的相位量$\phi$来替代时间$t$,下面将分别介绍两种类型的DMP。
2. 离散型DMP
离散型DMP(Discrete DMP)是解决空间轨迹规划的问题的,之所以取这个名字是为了对应连续的节律型DMP,主要的目的是为了解决笛卡尔空间的轨迹规划问题。前面讲到非线性函数$f$的构造过程需要用到一个与时间无关的量$x$,这个$x$来自一个一阶系统(正则系统),满足以下关系:
\[\tau \dot x = - \alpha_x x \label{cs}\]其中,$\alpha_x$是一个常数,常数$\tau$与公式$\eqref{DMP}$的$\tau$保持一致。在这个系统中,不论给定的初值$x_0$是多少,该系统最终(当时间区域无穷的时候)都会单调地收敛到$x=0$状态,因此$x$可以看成一个相位变量,例如,当$x=1$的时候表示系统处于初始状态,当$x=0$的时候表示系统收敛到了目标状态。在实际编写程序的时候,常常将常数$\tau$移动到右侧来实现(相当于公式$\eqref{cs}$变作$\dot x=-\tau \alpha_x x$),以方便直接表示和计算$\dot x$,也与公式$\eqref{DMP}$中的$\tau$起同样的速度调制作用。
系统的两个参数$\alpha_x$和$\tau$将会影响到系统的收敛速度。本文附带的代码中,cs.py这个文件中实现了Canonical System的全部内容,从测试代码中可以看到,给定不同的$\alpha_x$和$\tau$,我们可以得到不同的实验结果:
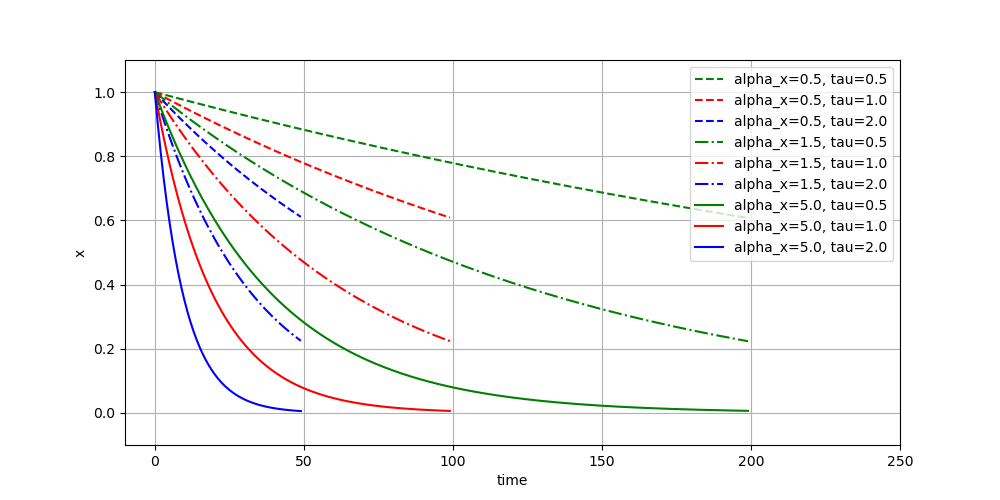
可以看到,系统的收敛速度与$\alpha_x$和$\tau$的值成正相关。
现在回到非线性项$f$上来,为了保证系统收敛到目标状态$g$的时候,$f$也收敛到0,从而不再对系统的控制过程产生影响,$f$被重新定义为:
\[f(x,g)=\frac{\sum_{i=1}^{N} \Psi_{i}(x) w_{i}}{\sum_{i=1}^{N} \Psi_{i}(x)} x\left(g-y_{0}\right)\]其中,$y_0$表示起始状态($y_0=y(t=0)$),$x$项可以保证$f$会随着$x$的收敛而消失,且$g-y_0$决定了$f$的“幅值”,用于后续对轨迹的形状进行“放缩”,实际放缩的大小为$\frac{g_{new}-y_0}{g_0-y_0}$。
注意:这里其实是有点问题的,例如对于轨迹的目标位置与起始位置都在同一个位置的情况来说,$g-y_0=0$,那$f$就没有存在的意义了,因此,对于示教轨迹的起始点和目标点一致的情况这里不再适用,注意,对于三维空间中的轨迹来说,不是每个维度都要一致才叫一致,只要其中有任何一个维度是一致的,那么这个维度的$f$就会失效,我们就无法学习得到轨迹的形状,在使用的时候要注意这一点。Schaal团队在2013年的论文中提出了解决这个问题的办法,但是在这个版本的教程里面我们不做介绍,感兴趣的读者可以阅读论文的第19页,这个版本的教程只介绍最基本的DMP方法。
基函数$\Psi_i(x)$的定义为径向基函数:
\[\Psi_{i}(x)= \exp \left(-h_i(x-c_i)^2 \right) = \exp \left(-\frac{1}{2 \sigma_{i}^{2}}\left(x-c_{i}\right)^{2}\right)\]其中,$\sigma_i$和$c_i$分别表示基函数$\Psi_i$的宽度和中心位置,这些参数都是需要在模型的学习阶段通过示教轨迹得到的。
那么如何设置这些参数呢,下面我们借用Travis DeWolf的几张图片来展开说一下基函数的参数学习过程。
首先,我们来看每个基函数的中心值选择问题。
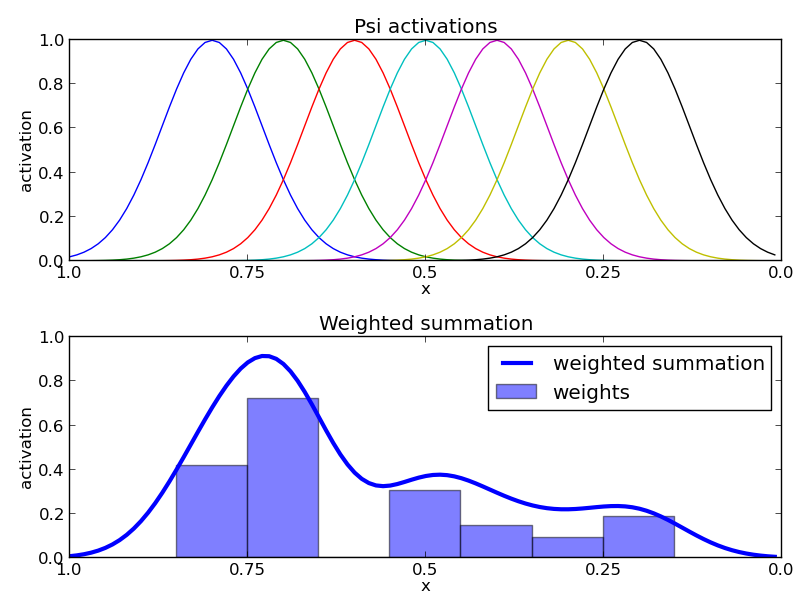
前面已经提到,正则系统(CS)从任意给定的初始值(比如$x_0=1$)开始,随着时间的流逝,最终都会收敛到$0$,而这些高斯基函数是随着正则系统的$x$分布的,如上图的第一张图所示,假设正则系统是线性收敛的,则$x$的递减速度为恒定速度,那么高斯基函数的分布要覆盖从$x=1$开始到$x=0$的全部位置,其中心值应该尽可能覆盖均匀一点,这样可以在尽量广的空间上都能有足够的基函数用于拟合复杂的曲线。而上图中的第二张图中展示了给不同的高斯基函数分配的权值$w_i$,这些权值与基函数$\Psi_i$的乘积之和就是我们要的非线性项。而由于正则系统最终都能收敛到$0$,从而保证了随着时间的流逝,非线性项起的作用越来越小,系统最终会趋于稳定,而不会发散失控。
但实际上,正则系统并不是线性收敛的,正如前面的图中我们可以看到,给定不同的$\alpha_x$和$\tau$,我们可以得到不同收敛速度的正则系统,而且收敛速度都是由快到慢,在初始位置附近收敛速度非常快,而在目标位置($0$)附近收敛速度逐渐趋于平缓。如果我们仅仅是按照正则系统$x$的分布来均匀布置高斯基函数,那么从时间的维度上来看,我们就会得到类似如下的基函数分布:
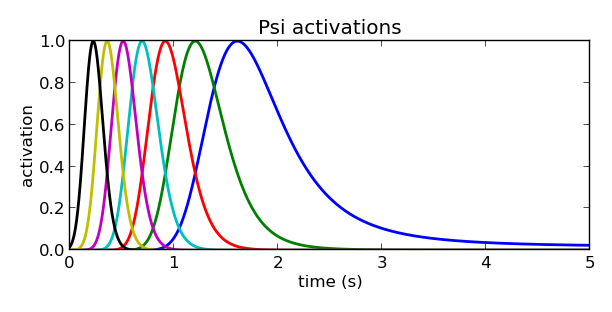
从图中不难看出,在时间的维度上,大部分的高斯基函数都集中在初始时刻附近,而随着时间的进行,基函数所起的作用越来越小,这样会导致在曲线拟合的初始阶段效果很好,而在趋于目标位置的末段曲线的拟合效果变差,甚至是无法拟合。因此,我们需要改变一下策略,使得高斯基函数能够在时间的维度上也尽量分布均匀,保证整条曲线的拟合效果。
我们再来看正则系统的收敛过程:
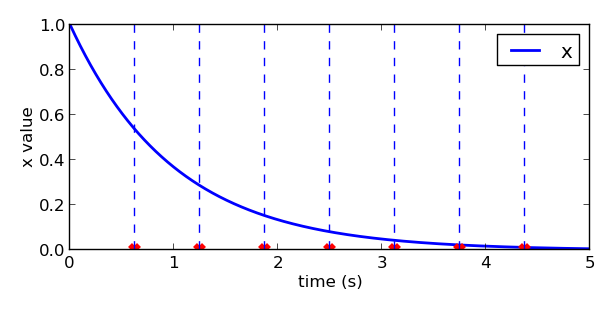
如果要在时间上分布均匀,例如按照图中所示的红点分布,那么我们就应该选择这些时刻的$x$值作为高斯基函数的中心位置$c_i$,从而保证在时间的维度上高斯基函数是均匀分布的。
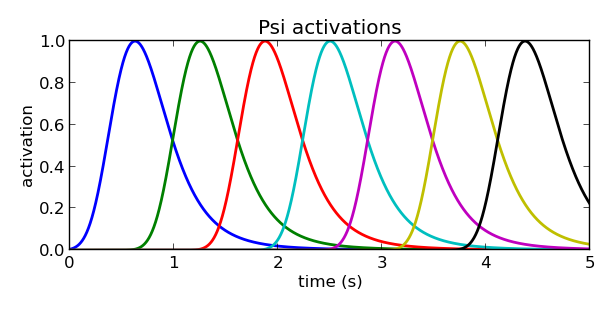
中心值确定了以后,接下来就是基函数的宽度(方差$\sigma_i$)了。我们刚刚已经说了,为了在时间的维度上得到均匀分布的基函数,我们需要根据时间和正则系统来倒推寻找合适的$x$作为基函数的中心值,让中心值位置在时间的维度上分布均匀,那么基函数的宽度如何设定呢?思考一下,正则系统$x$的收敛速度是越来越慢的,那么如果我们把每个基函数的宽度在$x$的维度上设定为一样的,就会导致早期的基函数持续时间短,而后期的基函数持续时间长。因为时间越往后,经过同样宽度的$x$所需的时间越多,从而导致在时间的维度上出现基函数的宽度不一致的问题,时间约靠后的宽度越大。因此,基函数的宽度应该随着时间的递增而递减,从而保证在时间的维度上,每个基函数的宽度也是均匀的。
这方面的技巧在原作者的论文中没有提及,在Travis DeWolf的博客中,他给出的答案是:
\[h_i = \frac{\#BFs}{c_i}\]其中,$#BFs$表示基函数的数量,$c_i$表示那个基函数的中心值。
至此,基函数的中心值问题和宽度问题我们已经有了解法,在实际使用时可以根据时间和正则系统的参数分别计算得到。
3. 节律型DMP
节律型DMP(Rhythmic DMP)是解决连续周期的节律型轨迹规划问题的,例如关节空间的周期性关节角度规划问题。周期性曲线我们需要进行改变和泛化的往往是曲线的幅值与频率,从而获取不同的曲线来满足不同的任务需求。
节律型DMP的计算过程与周期型DMP一致,但是有几处不一样的地方,主要是所采用的正则系统(CS)不一样,所使用的基函数构造方法不一样,非线性项$f$的构造方法也稍有不同,我们分别来看。
前面讲到非线性函数$f$的构造过程需要用到一个与时间无关的量$x$,与离散型DMP的正则系统收敛到目标状态$0$不同,节律型DMP的$x$($\phi$)来自另一个正则系统,该系统收敛于一个极限环(Limit cycle),公式定义为:
\[\tau \dot \phi = 1\]其中,$\phi \in [0, 2 \pi]$是在极坐标下的相位角度。
我们假定轨迹的幅值定义为$r$,则非线性项$f$的定义为:
\[f(\phi, r)=\frac{\sum_{i=1}^N \Psi_i w_i}{\sum_{i=1}^{N} \Psi_i} r\]其中,基函数$\Psi_i$为冯米塞斯函数,定义为:
\[\Psi_i = \exp \left(h_i(cos(\phi - c_i) - 1) \right)\]有了上面的幅值和基函数还不够,我们还需要明确目标状态$g$。
在离散型DMP中,目标状态是轨迹的末端位置,而在节律型DMP中,目标状态是轨迹的中心位置(或者平均位置)。我们可以理解为在做周期性运动时,轨迹会“围绕”这个中心位置做往复运动。
对于周期性轨迹来说,我们还希望能够改变轨迹的幅值,在这里可以通过$r$来控制曲线运动的幅值。在DMP模型的参数学习阶段,我们可以设置$r=1$,这样可以保证DMP可以学习到与示教曲线一样的幅值,而在轨迹复现阶段,我们可以通过给定不同的$r$来得到不同的幅值,例如$r=0.5, r=2.0$可以分别得到示教曲线的一半幅值和两倍幅值。
4. DMP模型学习和轨迹复现
4.1 DMP的学习过程
前面我们已经系统的介绍了DMP的两种类型,分别适用于离散型轨迹建模和周期节律型轨迹建模。其中,给定示教的轨迹$[y_{demo}, \dot y_{demo}, \ddot y_{demo}]$,则DMP模型的参数可以得到。
参考前面的公式,需要确定的模型参数有PD控制器的$\alpha_y, \beta_y$,基函数的个数$N$、宽度$\sigma_i$、中心值$c_i$和权重$w_i$,正则系统的参数$\alpha_x$。其中,常数型的参数$\alpha_x, \alpha_y, \beta_y, N$都是需要事先给定的,我们可以根据经验值手动指定,本文附带的代码中$N$默认值为100,其他的参数在作者2012年的论文中都有指定默认值,例如$\alpha_x=1.0, \alpha_y=25, \beta_y = \alpha_y / 4$。当然,我们也可以通过使用其他方法来学习得到这些参数,比如强化学习(Reinforcement Learning),这里我们不展开讨论。
前面我们已经知道了如何求解每个基函数$\Psi_i$的中心值$c_i$和宽度$\sigma_i$,对于$f$中的权重$w_i$的参数确定,论文采用了局部加权归回方法LWR(Locally Weighted Regression)来学习得到。当然,也可以采用其他方法来实现,采用LWR方法的原因是它的计算效率高,对于这种one-shot模仿学习来说,实时性比较好,而且LWR中每个模型Component的学习过程是相互独立的。通过变换公式$\eqref{DMP}$,并给定示教轨迹$[y_{demo}, \dot y_{demo}, \ddot y_{demo}]$,我们可以得到需要学习的$f_{target}$:
\[f_{target} = \tau^2 \ddot y_{demo} - \alpha_y(\beta_y(g-y_{demo})-\tau \dot y_{demo}) \label{f target}\]而从前面我们已经分析了非线性项$f$是通过基函数加权得到的,因此我们需要构造损失函数,然后使用最优化方法LWR来学习得到这些基函数的模型参数。对于每一个基函数$\Psi_i$对应的权重值$w_i$,我们可以构造如下的平方损失函数:
\[J_i = \sum^P_{t=1} \Psi_i(t) (f_{target}(t) - w_i \xi(t))^2 \label{loss}\]然后使用优化方法来求解上式使得$J_i$最小化。其中,$P$表示整条轨迹的总时间步数(即$t/dt$),对于离散型DMP,$\xi(t)=x(t)(g-y_0)$,对于节律型DMP,$\xi(t)=r$。公式$\eqref{loss}$是一个加权线性回归问题,它的解为:
\[w_{i}=\frac{\mathbf{s}^{T} \boldsymbol{\Gamma}_{i} \mathbf{f}_{\text {target }}}{\mathbf{s}^{T} \boldsymbol{\Gamma}_{i} \mathbf{s}}\]其中,
\[\mathbf{s}=\left(\begin{array}{c} \xi(1) \\ \xi(2) \\ \ldots \\ \xi(P) \end{array}\right) \quad \boldsymbol{\Gamma}_{i}=\left(\begin{array}{cccc} \Psi_{i}(1) & & & 0 \\ & \Psi_{i}(2) & & \\ & & \ldots & \\ 0 & & & \Psi_{i}(P) \end{array}\right) \quad \mathbf{f}_{\text {target }}=\left(\begin{array}{c} f_{\text {target }}(1) \\ f_{\text {target }}(2) \\ \ldots \\ f_{\text {target }}(P) \end{array}\right)\]这里不对推导过程展开,感兴趣的读者可以参考原论文。
4.2 DMP的轨迹复现
在前面的DMP模型学习以后我们已经得到了模型的各个参数,那么轨迹复现的时候就只需要设定好不同的参数再计算对应的非线性项$f$,根据公式$\eqref{DMP}$即可复现出满足任务需求的轨迹,在附带的代码中我们给了一些简单的例子。
4.2.1 离散型DMP
示教曲线为一个二维曲线,基函数的数量为100:
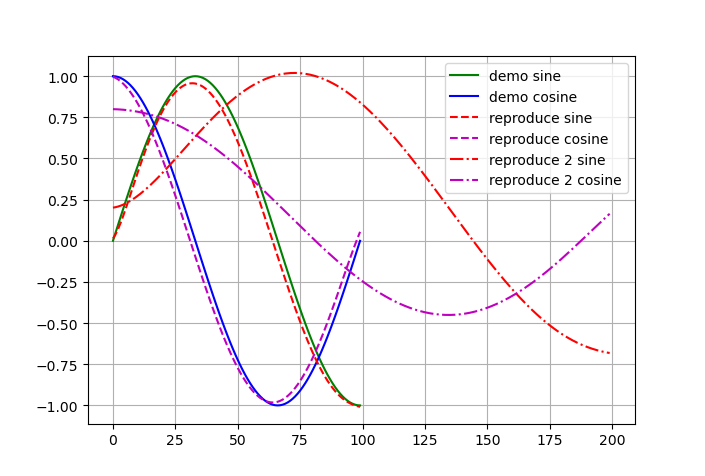
其中,实线表示示教曲线。reproduce曲线表示DMP模型学习以后的轨迹复现结果,reproduce 2 曲线表示给定了不同的轨迹起点和轨迹目标点以后DMP模型的轨迹复现结果。
4.2.2 节律型DMP
对于节律型DMP,分别测试了数据为1维和2维的情况:
数据为1维的情况,基函数的数量为200:
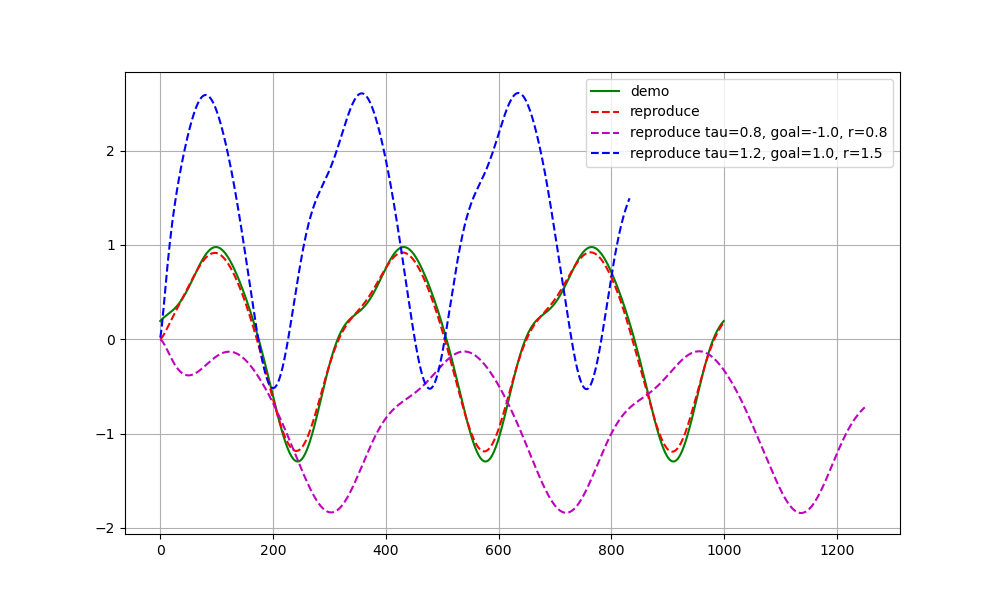
数据为2维的情况,基函数的数量为500:
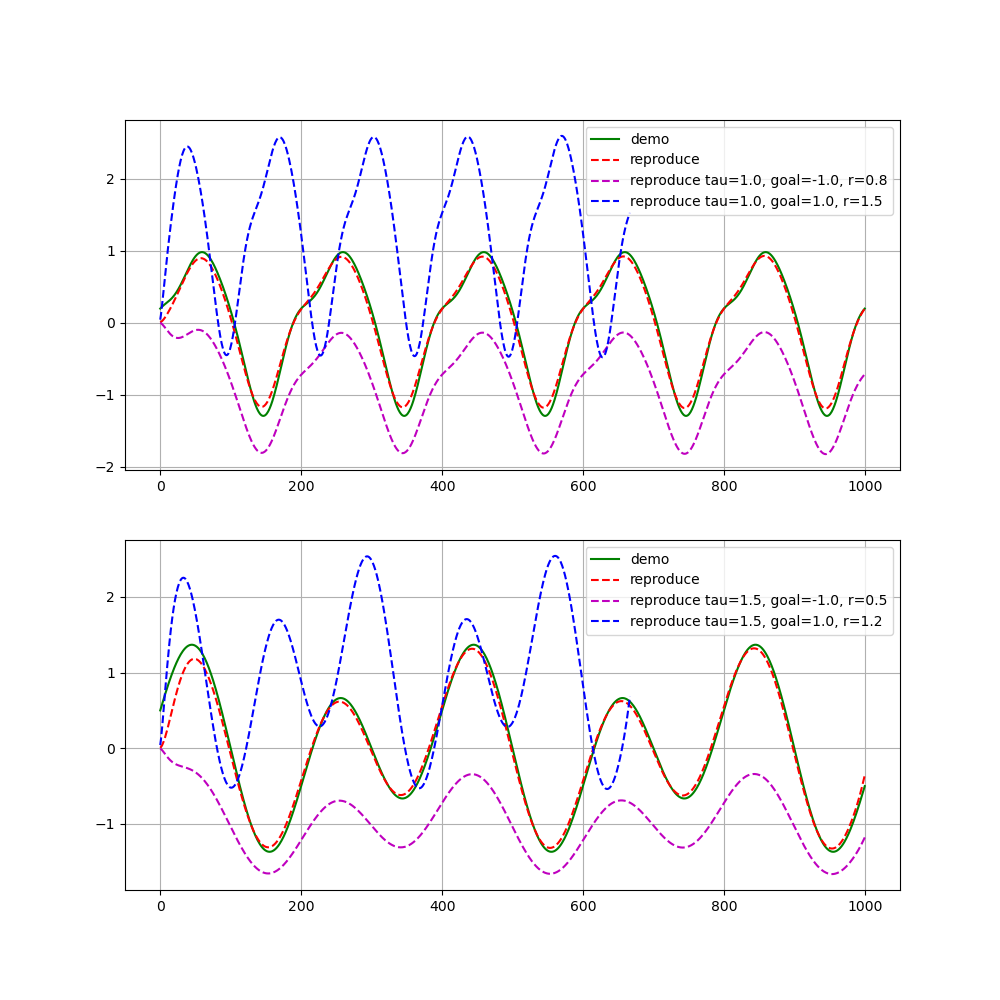
以上就是两种基本的DMP的公式介绍和实验结果了。在这里,我们要提醒读者,对于离散型的DMP,这个版本的DMP无法解决轨迹起始点和终点非常接近的情况下的轨迹学习问题,对于节律型的DMP,还存在当给定的$r$或$g$不连续时出现轨迹跳跃的情况,这些问题作者Schaal在2013年的论文中第19页有介绍部分解决办法,我们将在后续的教程里面给出对应的改进版DMP,欢迎持续关注。
5. 机械臂仿真应用
在前面的章节里面我们已经介绍了两种基本类型的DMP,在这里,我们将会结合CoppeliaSim中的UR5机械臂,使用这两种DMP方法来做一个简单的Demo,方便读者能够直接基于现有的Demo进行自己的任务处理。
5.1 离散型DMP实验
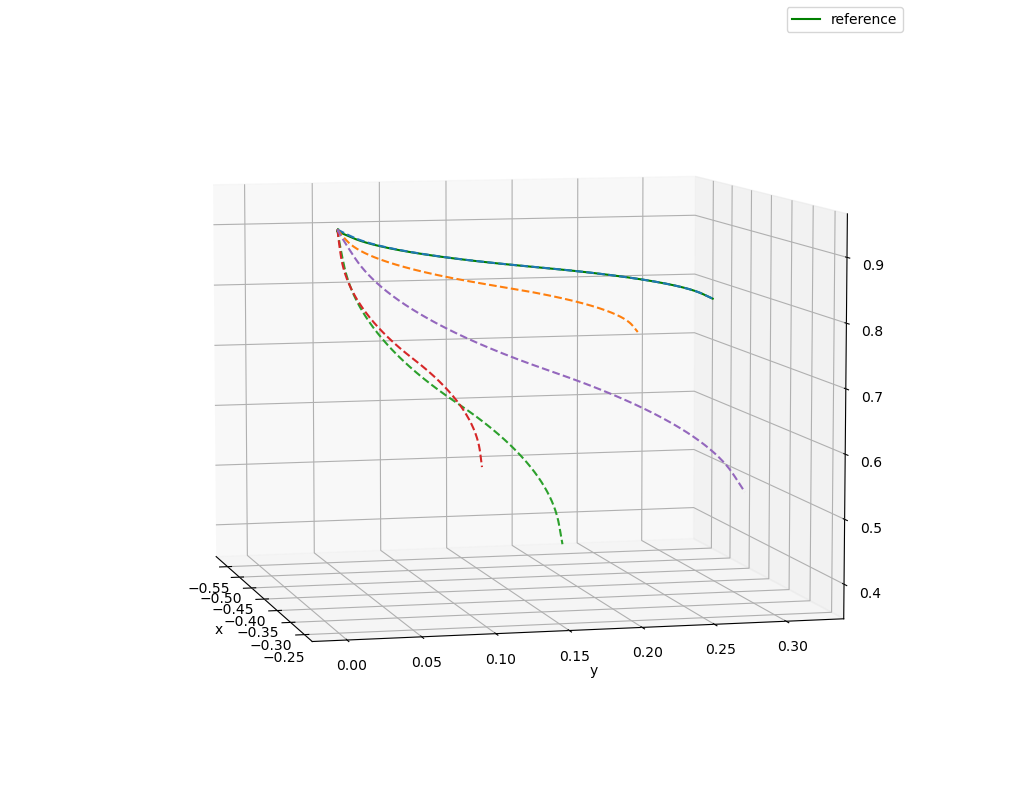
使用DMP建模UR5机械臂的末端轨迹,并给定不同的起点位置和目标位置,DMP可以生成符合任务要求的轨迹。

给定同样的起点,只是改变目标位置,DMP生成的轨迹为:
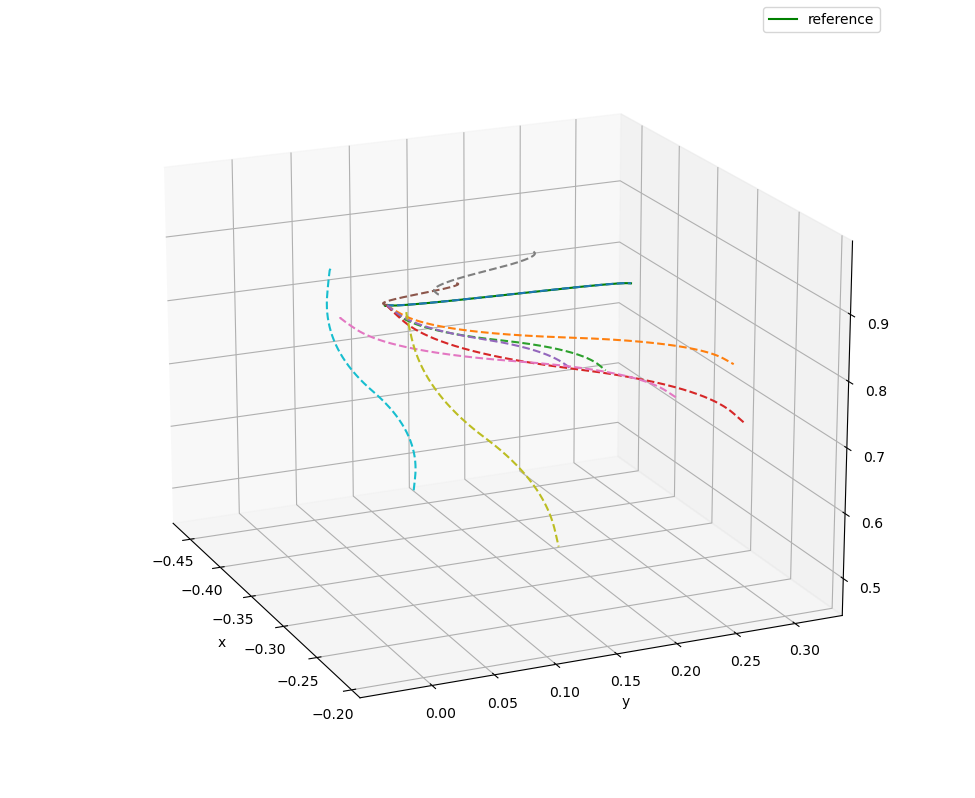
既改变初始位置,也改变目标位置,DMP生成的轨迹为:
5.2 节律型DMP实验

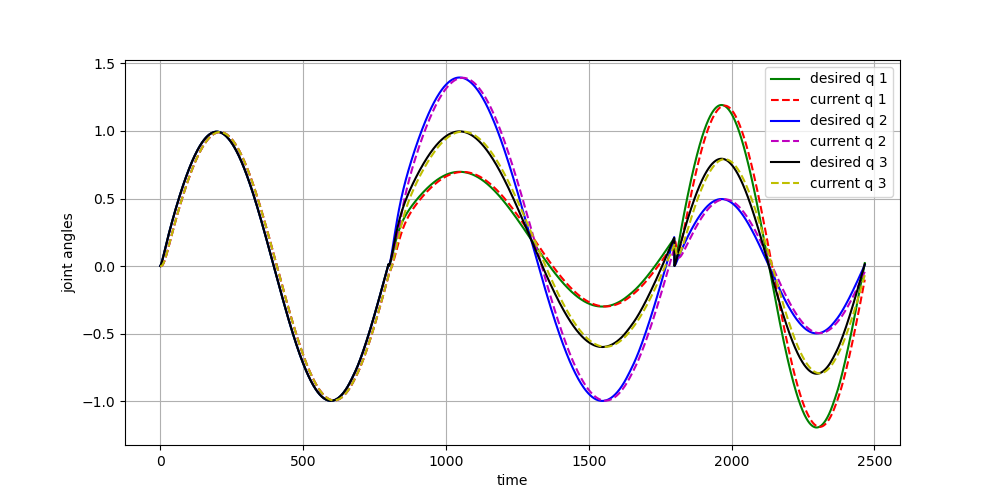
给定了三个关节角度的参考轨迹,并通过DMP来生成不同的轨迹。
以上两个实验的源代码都可以在我的Github仓库上找到,地址为:chauby/PyDMPs_Chauby (github.com),读者如果用得到,请自行下载使用。
参考文献
其中,原作者的两篇论文已经放在了源代码的paper目录下。
